I dreamed about moving the requirements specification to code. Am I happy with Spec-Driven Development now?
One problem with software development is (and still is) that related artifacts are distributed across various tools. Tasks are set in Jira, documentation in Confluence, and code in GitHub or GitLab. The requirements and documentation are unequivocally spread across those.
If managed right, that is not a huge deal. Unfortunately, I rarely saw such cases in practice. Frequently, the requirements management on large enterprise projects goes rogue as soon as its initial owner/founder passes on. That contributes to a mental block that some developers had issues with (or simply don't like) reading requirements.
And I could relate to that: the additional cognitive load of tracking all the task details from various sources and putting them into one picture. Plus, those requirements might be badly written. Some context might be missed, taken for granted, and so on.
I understand those who ignore the specification and go directly to the source of truth or their proxy. Don't support, but understand.
Fighting in the war for unification, I became an advocate for the docs-as-code approach where appropriate. Your service docs, as Markdown files, are under the same Git versioning as the source code. As a definition of done, the developer updates the docs along with the code. They no longer forget to update the docs. Plus, the docs are in code and are more clearly structured. At least, on my projects.
That trick did not meet the requirement, though. I've never tried to implement that in practice; I only did a few thought experiments. My main issue is that, unlike the documentation, which aligns with the functional parts of an actual system, the requirements do not match the architectural design.
Simply put, requirements may span multiple modules, so where the heck am I supposed to store them? And if they concern several repos? My thought experiment ended up with a separate Git repository for requirements, which is the worst idea, even compared to Confluence.
Now, in 2026, docs are essential to the context for AI tools. So the proponents of docs-as-code had an advantage there, since they skipped a step involving Confluence MCP.
AI also changes the perspective on requirements.
The requirements specification quickly becomes irrelevant, regardless of the development work. Sometimes even quicker. And after that, the source code becomes the source of truth, the final outcome of the work.
Now, code is disposable and can be easily regenerated by AI agents with a prompt and a single click. That shifts the industry to search for a source of truth elsewhere, something deterministic to rely on in the brave new undeterministic world.
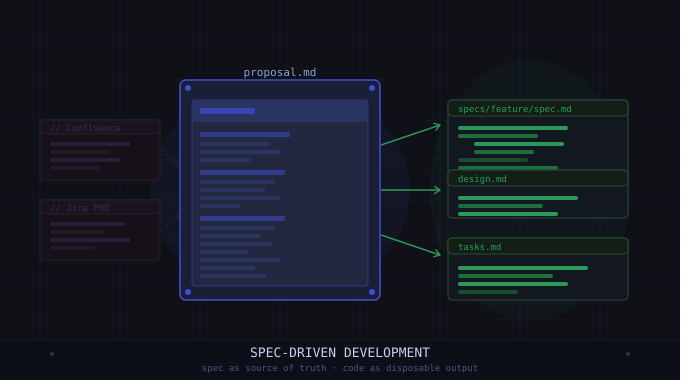
So, the Spec-Driven Development (SDD) approach takes the stage. And now everything is centered around the requirements. But it is not how we, the old guard of business analysis, expected it to be.
Simply put, SDD is a paradigm where a structured specification drives code generation by AI agents. The approach itself is not new, as it has been widely used for interface definition and generation in formats such as OpenAPI and thousands of other Domain-Specific Languages.
The spec is consumed by a machine that produces related code. The difference with AI is that the outcome is no longer deterministic, but the spec is. And the scale is different, as before, we could generate some layers using code generators. With AI agents, we can generate anything at any scale, limited only by the price of tokens.
Developers no longer need to read requirements. They won. Kind of.
Requirements engineering shifts to prompt and context engineering to put that machine-consumable contract into the black box and get the expected result. As much as expected, as is possible in its undeterministic nature.
Now, requirements shall not be forgotten artifacts after the development is done. For large projects, it is essential to keep the spec as the source of truth, always up to date with the implementation, because it is the critical aspect of the context.
To keep context concise, it is better to structure it and integrate it with the code (ideally with traceability). So my dream is coming true. Requirements move to code. Bye-bye Confluence and user stories in Jira.
We can keep PRDs and BRDs for manager-humans to read for some time. But they'll likely put it into ChatGPT and ask it to summarize. Putting PRD into LLM for code generation, like all that vibecoding, is considered an antipattern. So those business-oriented artifacts, as we know them, may go away.
Is that the future for requirements I was expecting? Obviously, not.
But we live in strange times when companies try to ride the waves, imposing an illusion of control in the name of cost efficiency. And SDD was revived exactly for that purpose.
There are dozens of tools like OpenSpec, MUSUBI, Spec-Kit, and Superpowers. In a year, the list might be entirely different.
Oh, Brave New World!