How I stopped doing Product Management and became obsessed with AI evals

That title isn't clickbait: it's what actually happened. Over the last three months, I've spent 90% of my time obsessing over whether our AI search returns the right results. Not writing PRDs. Not in stakeholder meetings. Just testing, scoring, and re-testing AI outputs.
Only recently did I learn that there is a trending term for what I am doing: AI evals. I thought that was "quality assurance" or "testing". But AI Evals is a sexier name for selling courses.
Jokes aside. The main reason the industry began separating it from traditional QA frameworks is the non-deterministic nature of the output. Different results from the same input were considered as the definition of madness.
Now it is our new reality.
There is another question to explore: why are AI evals considered a new critical skill for product managers? (to sell some courses, of course).
I won't give you a theory about AI evals. Instead, I will summarize my experience evaluating AI-based search capabilities using the RAG architecture.
Even though I didn't know such fancy words at that moment.
The Three Dimensions of AI Evaluation
Let's start with definitions.
Selecting the right provider and LLM is an essential question you need to answer when developing an AI feature. There are three main aspects:
- cost
- quality
- speed
Cost is the amount of money you pay a vendor for API calls and for using its infrastructure. It could also be specific spending on the internal infrastructure if using on-prem. I shared my thoughts on cost vs. value in a previous article, so that I won't repeat myself here.
Quality means a model covers all required use cases: it returns the expected output for a given input.
Speed means how quickly an LLM processes and responds to user queries. That might be critical for some applications. In my case, speed is not a concern, so my evals focus on cost and quality.
From Manual Chaos to Structured Testing
I needed to verify use cases for each LLM we believed had the right cost/quality balance. I created a few test cases covering every use case.
A test case looked like:
- user prompt
- A list of expected search results pulled from a database
- Expected response message
The next obvious step was to automate the test run, so you can document and later compare them. API calls in Postman are a good starting point (even though I personally recommend Bruno).
Simple request-response is not enough, so you need to build a trace that includes:
- user prompt
- system prompts
- data pulled into the context from the DB
- info about which agentic tool is called (or which step of the workflow)
- number of input and output tokens
I ran those test cases via the API across several models, documented the results in Excel, and visually compared them. Comparing search results from the DB is easy, especially when you have a unique identifier for each data object that is consistent across all environments. If I expected two objects but got one, then it is 5 out of 10. If both came, it is 10 points. No matches: no score, so the test is considered as failed.
LLM messages I subjectively scored from 1 to 10, from worst to best. The message is secondary to the search result. But if it is lower than 4, it is a failure.
As a result, I scored each test result based on those (quite subjective) points, along with calculated token consumption. Based on that data, we decided which LLM to proceed with.
Not ideal, however, the criteria used in the initial model evaluation serve as a foundation for comprehensive "AI evals".
Building an Evaluation Framework
Firing several dozen API calls and comparing the results visually is not a scalable approach. We started extending our agentic workflow by adding new tools with their prompts. We need to test new features and make sure we do not introduce regressions.
We tried to keep each step as isolated from the others as possible, so prompt changes to one step won't affect the others. But even so, any unintentional or poorly thought-out change to a prompt could corrupt the user case. Increasing complexity increases the likelihood of it happening.
We had to build our own testing framework to ensure the quality of existing and upcoming features while keeping migration to newer models in mind.
We've documented in an Excel spreadsheet a few dozen test cases, each associated with a specific use case and related to a particular type:
- simple case - simple successful transaction: request-response
- complex case - multiple transactions before success: request-clarification (some number of them)-response
- edge cases - out of the scope requests to check how the model handles such situations
From them, we've selected a bunch for automation and converted them to JSON.
Here is an example of a test case:
{
"testCaseId": "TC_001",
"description": "Check simple request for customer creation with clarification",
"testCaseType": [
"simple_search"
],
"userInput": {
"query": "create individual customer",
"clarificationNeeded": true,
"clarificationText": [
"for X app, version Y"
]
},
"expectedOutput": {
"expectedResponse": "Short message with 2-3 results about creating, updating customer account, or some customer details.",
"documentComplexIds": [
"07d17a43-2065-324e-a651-da8c966dd89b",
"6e5b6ea1-b04f-37e8-bba1-9cc619824a7a",
"f38194d0-72e8-3dcb-a46f-c8ceab7a929e"
]
}
}
My team created a tool that runs all or some of the selected test cases on a local machine, calling LLMs chosen from the list of providers defined in the configuration. It collects responses and writes them to test logs. Then it evaluates responses using another LLM and generates a CSV report.
It is straightforward for a simple case with one transaction. But a user can provide incomplete information, and the chatbot will ask clarification questions. We have a particular "interview" step to request additional information to make the search more precise. There is a matrix in a prompt that says when enough information is provided.
For test cases, we assume how many clarifications are required, then create a made-up dialog in which the model asks the questions we expect it to ask and responds with predefined responses.
Here is how it works:
The diagram shows the interview process flow, including decision points for when the system has enough information versus when it needs to ask clarification questions.
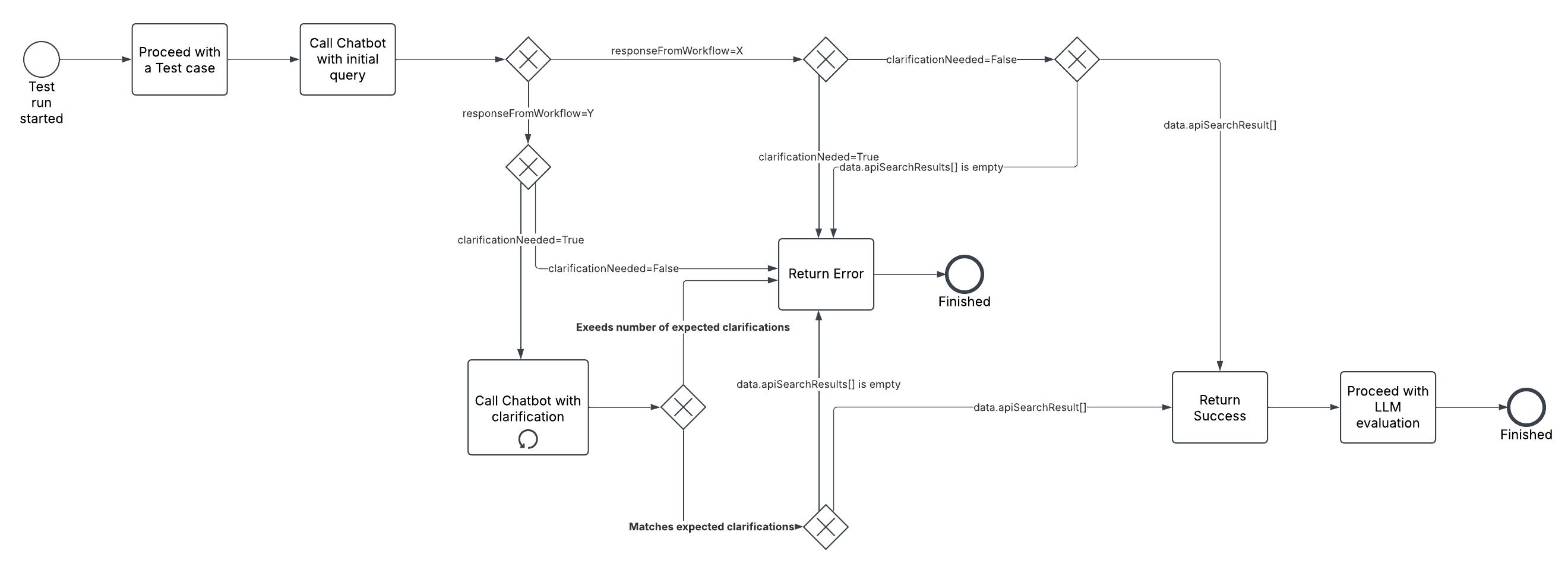
The problem is that the model can ask for more clarification than expected. And we consider it a failure because we want a smooth experience, not an annoying chatbot. So that's one of our evals: "Not to ask too many and irrelevant questions."
Three Types of Evals: Code, Search, and Message
Other evals we can frame into large groups:
- Validating output structure
- Matching search results from DB
- Evaluating message
Output structure and search results validations are so-called "code-based" rules, which you can develop "traditionally". We check whether we receive a valid JSON structure from LLM. Within that structure, we validate whether the required data has been provided, depending on the workflow.
Search result matching is a trickier process. LLM analyzes the data it receives from the DB, but returns only a UUID to reference a data object. That helps:
- Quickly validate if that UUID is not made-up
- Match with UUIDs provided in test cases
- Save some output token: we look up data using the UUID, and the user sees the required data
We went through several iterations to determine how to score LLM-provided search results against those we expect in test cases. The simplest is to set PASS if any UUID from a test case appears in a result. We tried to calculate a score based on how many results were returned vs. the number we expected. But that quickly becomes overhead, as it largely depends on interpretation.
However, another eval notifies whether there are too many search results. For example, the LLM returned one result we expected from a test case (which is already PASSED) and 9 other results. We allow non-mentioned results to appear, as LLM might consider some related data valuable for the user. But 1 of 10 is too big a ratio, so it raises a warning for us to double-check.
In message evaluation, we went in a different direction from simplification to more complex criteria while using another LLM-as-judge. It is a de facto standard because human evaluation does not scale, and it is too difficult to do such a process by algorithms. Here we have three metrics:
- Accuracy - How accurate the message is to the initial user request
- Relevance - How relevant the message is to the returned search results
- Safety - Whether tone is formal, respectful, and not harmful
All those are graded from 1 (the worst) to 5 (the best). All results below three do not pass.
Embracing Imperfection: The Non-Deterministic Reality
Our approach, with three dozen cases and the custom evaluation we built, helps us with regression immensely. We can migrate to other LLMs and experiment with prompts, ensuring a required level of quality. Still, we have manual test cases as we haven't figured out how to automate some scenarios or postponed them as less relevant.
We built rigorous test cases, and I spent hundreds of hours adjusting our prompts and driving implementation to achieve 100% success. After a few months, I gave up fighting, agreeing to loosen some of the cases and rebuild the evaluation criteria. The non-deterministic nature of the outcome made perfection unachievable.
Out of 30 cases, three or four occasionally fail during test runs due to variations in LLM answers. On bad days, 30% may fail at some point due to LLM performance degradation for unknown reasons. The next day, everything works fine.
The definition of quality as we knew from deterministic systems has gone. That drives me crazy, but I have to adapt as we all do.
Why This Became a PM's Job
I omit the cost question, but you must always keep it in mind. For LLM-as-judge, you can use a cheaper OSS model, but you still need to run cases and pay for tokens. Daily regressions might be too expensive for newer, more powerful LLMs.
I have a joke: while trying to optimize token consumption by 10%, I ran so many regression tests that the ROI is now unachievable for years. There's truth in every joke. So take the cost aspect here seriously.
In my decade-long career as a product person, I have never been so involved in defining evaluation criteria and testing. At some point, that was the only thing I was doing to make sure the AI search worked as expected.
That is because a product manager has a deep knowledge of the product, its audience, and its requirements. That adds to deep involvement with context (as a context dealer) and prompt engineering. It put us in the middle of the storm, and while seeking a new definition of a product role, it is a great place to ensure customer value delivery.
What's your experience with AI evals? Have you faced similar challenges with non-deterministic outputs? Share your thoughts in the comments below or connect with me on LinkedIn.