Conversion & Data Mapping
Previously, I mentioned an approach of "wrapping" a legacy system by providing a modern API layer as an abstraction to separate the Legacy from their clients. And migrate them to new APIs with the updated data format/new models. After that, you can proceed with the decomposition, not bothering the clients again.
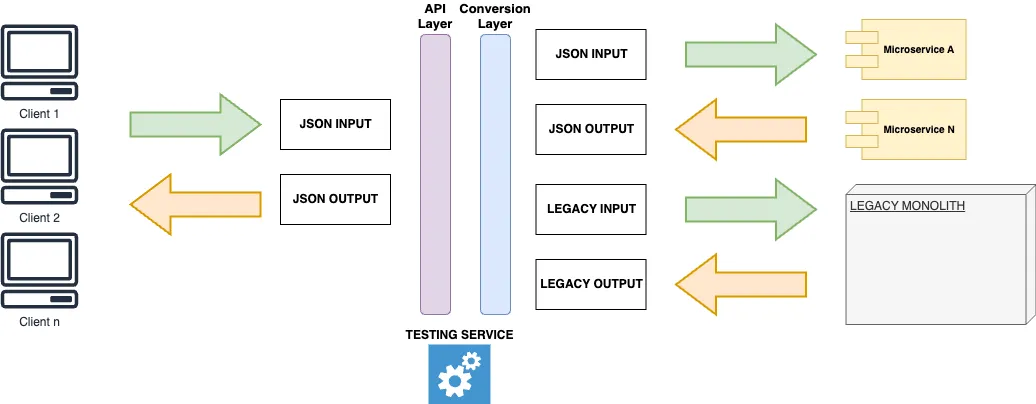
The "wrapping" strategy implies that the Legacy will still operate for some time alongside the new system, creating a seamless transition experience for consumers. That results in the conversion layer requiring data mapping as a BA artifact.
Let's talk about mappings
We already discussed the massive challenge of reinventing the Legacy Data Models, so let's assume you have already done it. Mapping is a data dictionary containing relationships among new and old attributes with helpful information for executing data conversion. That may include (in any format and combination):
- attribute name
- attribute position in a structure (e.g., JSON path)
- related Entity (especially ones not presented in the Legacy)
- related legacy attribute(s)
- data type (especially if there is a data type conversion)
- description of what that attribute means with any useful references
- any aggregation or other logic (you don't think it is always 1–1 mapping, right?)
A BA must combine and maintain the mapping throughout the project timeline. So, where and how to manage a mapping is an important question you'd better know the answer from the start.
I don't have numbers, but such data mapping for a legacy system is usually enormously big. Migrating it from one tool to another is not what you want to spend time on. So, let's see a few options.
Confluence
It might be an obvious choice if you work with the Atlassian products. But I wouldn't say it is suitable for large mappings due to poor performance and sometimes strange table formatting. Some paid plugins allow you to manage huge tables on multiple pages, but not in an out-of-the-box on-premise installation.
The main advantage is version management and integration with Jira. But problems may come when a senior stakeholder asks about exporting it to…
Excel spreadsheets
Let's be clear: that should be your first choice by default. Once, I had to migrate data mapping from Confluence to an Excel spreadsheet due to a stakeholder's request I could not deny. Only my Python skills saved me from the very dull routine. I made up a trivial script that parses Confluence's XML and converts it to a spreadsheet.
And you are right: since I had to support both mappings in Confluence and in Excel. But my script helped me to work that out and focus on the mapping in Confluence.
By the way, I was very proud that developers put my amateur Python code under the project's git repository to keep that script alongside the new system code.
Managing a considerable data mapping in Microsoft's Excel/Google spreadsheet is still challenging. But that is still better than Confluence (sorry, Atlassian). You can also attach that spreadsheet to a Confluence page if needed.
Versioning
Managing versions and access rights is still debatable and depends on project specifics. I recommend keeping the master version with ongoing changes where only a few people can edit it. Each release has a release mapping version copy as a separate file and stored somewhere else (Confluence, Sharepoint).
It is also possible to introduce versioning of each attribute. But it would be best if you had a solid reason to justify increased maintenance efforts. That can quickly end up as a burden.
And there is always an option to put it under a git and manage versioning there if you know how to do that.
Other mapping tools
I researched to find an alternative where I can keep and manage extensive mappings. But most of them were enterprise tools and part of a tooling vendor portfolio. They looked awful from the UI/UX perspective and cost too much. No manager will be happy to spend so much of the project budget on a license when Confluence and Excel are under your hands.
At some point, I was so desperate to start thinking about writing my own tool to manage data mappings. But I found that idea too altruistic and time-consuming to do it alone.
If you know a free tool to manage data mappings, please let me know in the comments or write me on LinkedIn.
Right now, Google Spreadsheets is the best available option. And maybe Notion, with its databases, can also work for large mappings.
What about XSLT?
At some point, the Team was considering the possibility of using XSLT to manage the data mapping. But we decided not to proceed with that approach because:
- Stakeholders from the business side can't read and understand that format. They prefer old-fashioned spreadsheets. So, you will have to maintain both artifacts and spend more time than you already spend on maintaining hundreds of attributes.
- Maintaining a massive mapping in one file is a challenge. However, decomposing it into multiple files adds more issues to resolve.
- Part of the mapping was from XML to JSON, but there was also a part in a COBOL data format. I don't think XSLT can handle this.
- Developers did not like that idea from the start for their reasons.
Testing conversion
We made both-side conversions in a separate microservice and provided a command-line interface for testing. Having a legacy input, we can convert it into the new format and back and check for a difference. Legacy outcomes are converted to the new format and back similarly.
However, a "converted" legacy data can have some expected differences from an "original" one. For example, in a COBOL structure, "0" may have the same meaning as a blank space. And we can't predict what we get from a client. But conversion shall have only one interpretation in a result.
Additionally, some intentional changes can be implemented for the conversion. Or some legacy structures can be omitted. They should be documented and considered by test and automation tests.
Legacy does not sleep
If a legacy system is operational and some critical business processes rely on it, it will continue evolving. It is unlikely that changes will happen in the existing attributes (remember, they need to maintain layers and layers of prehistoric logic), but new attributes may arrive.
A BA must be aware of such changes in the mapping until the Legacy is entirely replaced. In most cases, development is done by different teams and mostly in parallel to keep the new and old data layers consistent.
Piece of advice
A BA should know the meaning of each mapped attribute. Or at least think that they know. But when you inherit a mapping structure from previous BAs who left the project, some context is lost anyway. You may research Jira tickets, emails, and documentation, but some valuable information is lost anyway. Moreover, there might be non-discovered mistakes in the mapping.
It is easier to say that you must understand each attribute's definition and avoid thoughtless mapping, relying on intuition and presumable common sense. But that will help when you proceed to the next big step: decomposing the legacy business logic — that one we cover in the next chapter.